




Prompt to Response: Die Millisekunden-Reise deiner Frage
Hast du dich jemals gefragt, was passiert, wenn du eine Frage an ChatGPT, Claude oder ein anderes KI-System stellst? Hinter jeder scheinbar einfachen Antwort verbirgt sich ein komplexer, faszinierender Prozess aus modernster Technologie.
Station 1: Deine Anfrage wird in kleine Sprachbausteine zerlegt – Die Tokenisierung
Was passiert: Die KI zerlegt deine Frage in kleine Bausteine, genannt ‘Tokens’ – die grundlegenden Einheiten der Sprachverarbeitung. Diese können ganze Wörter, Wortteile oder sogar einzelne Zeichen sein (GeeksforGeeks, 2024) [1].
Beispiel: Stell dir vor, die KI spricht also eine besondere Sprache aus Puzzleteilen. Jedes Wort, jeder Satzteil wird zu einem Puzzleteil. So kann die KI deine Frage “lesen”. Beispiel: “Wie geht es dir?” wird zu den Puzzleteilen: [“Wie”, “geht”, “es”, “dir”, “?”]
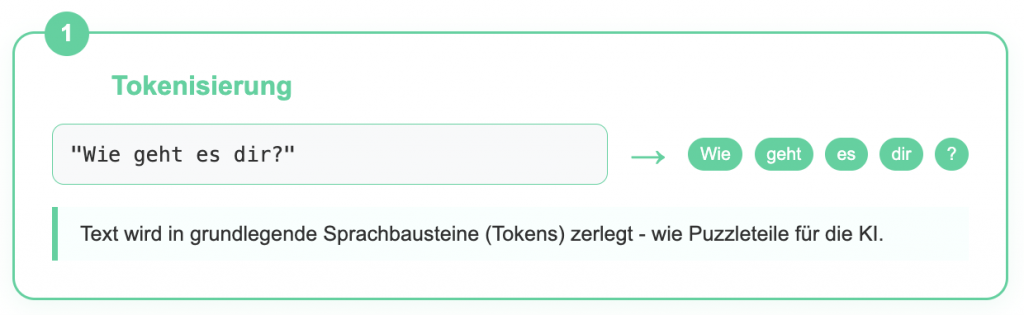
Token-Einsatz im gesamten Prozess:
- Input-Verarbeitung: Deine Frage wird sofort in Tokens zerlegt
- Interne Verarbeitung: Das Sprachmodell arbeitet ausschließlich mit Tokens
- Output-Generierung: Antworten entstehen Token für Token
Die große Wegegabelung: Drei verschiedene Systeme
Wichtig zu wissen: Es gibt 3 grundlegend verschiedene Systeme, die im Kontext von generativen Suchen arbeiten:
- Typ 1: Traditionelle LLMs (nur mit Trainingsdaten)
- Typ 2: Information Retrieval-Systeme (Klassische Suchsysteme)
- Typ 3: RAG-Systeme (Das Beste aus beiden Welten)

Typ 1: Traditionelle LLMs – nur Zugriff auf Trainingsdaten
- Was sie nutzt: Ausschließlich Trainingsdaten (static datasets) – riesige Mengen von Texten aus Büchern, Wikipedia-Artikeln und Webseiten, die beim “Lernen” der KI verwendet wurden
- Wie sie funktioniert: LLMs, die nur mit ihrem internen Wissen aus der Trainingsphase arbeiten. Sie haben einen Knowledge Cutoff – einen Stichtag, bis zu dem ihr Wissen reicht
- Output: “Aus meinem Wissen heraus ist die Antwort…”
- Vergleich: Wie ein hochgelehrter Professor mit perfektem Gedächtnis, der nur Wissen bis zu einem bestimmten Datum besitzt
Stärken:
- Extrem schnelle Antworten, da alles im “Gedächtnis” gespeichert ist
- Sehr breites Allgemeinwissen aus den Trainingsdaten
Schwächen:
- Wissen kann veraltet sein oder wichtige Lücken haben
- Keine Informationen zu Ereignissen nach dem Knowledge Cutoff
- Bei schnell verändernden Themen (Politik, Technologie, aktuelle Ereignisse) potenziell unvollständig
Typ 2: Information Retrieval-Systeme – IR-Systeme
- Was sie nutzen: Spezialisierte Suchsysteme, die in externen Dokumentensammlungen, Datenbanken oder Wissensdatenbanken suchen – können sowohl statische als auch dynamisch aktualisierte Datenquellen durchsuchen
- Wie sie funktionieren: Information Retrieval (IR) bedeutet “Informationen wiederfinden” – diese Systeme sind für präzise Suche und Informationsauffindung in großen, oft spezialisierten Datenmengen optimiert, anstatt nur das zu nutzen, was beim Training gelernt wurde
- Output: z.B. eine Rangliste relevanter Dokumente oder Textpassagen mit Metadaten
- Vergleich: Wie ein spezialisierter Bibliothekar, der dir sagt: “Hier sind die 10 relevantesten Bücher zu deiner Frage”
Klassische Beispiele:
- Bibliothekskataloge (zeigen relevante Bücher an)
- Traditionelle Datenbank-Suchfunktionen
- Google’s Suchergebnisliste (ohne KI-Summary)
- Unternehmensdokument-Suchsysteme
Stärken:
- Sehr schnell und präzise bei der Suche in spezialisierten Datenmengen
- Zugriff auf aktuelle und domain-spezifische Informationen
- Hohe Genauigkeit beim Finden relevanter Quellen
Schwächen:
- Du bekommst die relevanten Informationen, musst aber selbst die Antwort daraus extrahieren
Typ 3: Retrieval Augmented Generation-Systeme – RAG-Systeme
- Was sie nutzen: Kombinieren Typ 1 + Typ 2 + intelligente Verknüpfung – LLM-Trainingsdaten mit externen Informationsquellen (statische wie Dokumente/Datenbanken oder dynamische wie Live-Online-Suche)
- Wie sie funktioniert: RAG “supplements the LLM’s internal representation of information” – ergänzt das interne Wissen mit externen Quellen
- Output: “Basierend auf den gefundenen Dokumenten/Informationen und meinem Wissen ist die Antwort…”
- Der entscheidende Durchbruch: Das IR-System (Typ 2) findet die relevanten Informationen, das LLM (Typ 1) liest sie und formuliert eine verständliche Antwort
- Vergleich: Wie ein Experte mit perfektem Gedächtnis, der zusätzlich einen Assistenten hat, der für ihn recherchiert, ihm die Ergebnisse vorlegt, und er dann eine fundierte Antwort formuliert
Stärken:
- Intelligente Verknüpfung von gefundenen Informationen mit dem internen Wissen des LLMs für kontextuell passende, zusammenhängende Antworten
- Kombination aus allem – internes Wissen + externe Datenquellen + intelligente Antwortgenerierung + optional aktuelle Online-Informationen
Es gibt mehrere RAG-Varianten:
- Klassisches RAG: Nutzt vorindizierte Wissensdatenbanken (Vektor-DBs) mit statischen Dokumenten
- Hybrid RAG: Kombiniert verschiedene Datenquellen und Retrieval-Techniken
- Live/Web-RAG: Nutzt Live-Internet-Suchen als Datenquelle für RAG-Systeme
Wichtige Entwicklungen 2025: RAG hat sich 2024-2025 stark weiterentwickelt zu multimodalen Systemen und Real-Time-Ansätzen (NVIDIA, 2025) [2].
Wie Unterscheiden sich traditionelle LLMs von klassischen IR-Systemen und RAG?
Typ 1 – Traditionelle LLMs:
- Nutzt ausschließlich interne Trainingsdaten = arbeitet nur mit dem beim Training gelernten Wissen (statische Datenbasis mit Knowledge Cutoff)
Typ 2 – IR Systeme:
- Nutzt externe Datenquellen = können sowohl statische als auch dynamische Quellen durchsuchen
Typ 3 – RAG Systeme:
- Kombinieren Typ 1 + Typ 2: intelligente Verknüpfung von Internal-Knowledge (Trainingsdaten) mit externen Informationsquellen (statische wie Dokumente/Datenbanken oder dynamische wie Live-Online-Suche)

→ Station 2 (nächster Abschnitt) gilt nur für Typ 3 (RAG-Systeme)!
Station2: Die KI verarbeitet deine Sprache – Text Preprocessing
Daher, wenn du mit einem RAG-System arbeitest, passiert jetzt etwas Faszinierendes…
1. Deine Anfrage wird in verarbeitbare Segmente unterteilt – Chunking
Was passiert: Große Dokumente müssen erst in handliche Stücke geteilt werden – das nennt sich “Chunking”. Die KI teilt dabei nicht willkürlich, sondern folgt konkreten Strategien:
Die 5 wichtigsten Chunking-Strategien:
- Fixed-Size: Alle 500 Token oder 2000 Zeichen wird geschnitten
- Sentence Chunking: Schnitt an jedem Satzende
- Smart Chunking: Die KI erkennt Themenwechsel und schneidet dort
- Überlappungs-Chunking: Ein kleiner Teil wird wiederholt, damit kein Kontext verloren geht
- Semantisches Chunking: Schnitt nur dort, wo sich die Bedeutung ändert
Beispiel: Ein 50-seitiges Handbuch wird in 200 sinnvolle Textabschnitte geteilt, die jeweils ein Konzept erklären.

2. Die KI übersetz die Chunks in Zahlensprache – Embeddings
Was sind Embeddings? Nachdem der Text geteilt wurde, bekommt jeder Chunk eine einzigartige “DNA” aus Zahlen.
So entstehen die Zahlen-Codes konkret:
- Zufälliger Start: Jedes Wort bekommt erstmal zufällige Zahlen
- Millionen-Training: Die KI liest Millionen von Sätzen und verschiebt die Zahlen
- Kontextlernen: Bei “Die schnelle schwarze Katze springt” werden die Zahlen von “Katze” in Richtung “schnelle”, “schwarze”, “springt” verschoben
- Optimierung: Nach Millionen Wiederholungen haben ähnliche Wörter ähnliche Zahlen-Codes
Wichtig zu verstehen:
- 1 Chunk = 1 Embedding
- Jeder einzelne Chunk wird zu einem eigenen Zahlen-Code umgewandelt
- Aus 200 Chunks werden also 200 separate Embeddings
- Jedes Embedding ist wie eine “GPS-Koordinate” für die Bedeutung des Chunks

3. Das intelligente Bedeutungsarchiv – Vektordatenbanken
Was ist eine Vektordatenbank? Ein spezieller Speicher für all diese “Bedeutungs-Barcodes”. Statt alphabetisch wird nach Bedeutung sortiert.
So werden Chunks und Embeddings gespeichert: Die Vektordatenbank funktioniert wie eine riesige Tabelle:
- Spalte 1: Original-Chunk-Text (“Welpen brauchen viel Aufmerksamkeit…”)
- Spalte 2: Embedding (die 1536 Zahlen: [0.2, -0.8, 0.5, …])
- Spalte 3: Metadaten (Quelle: Hundebuch, Seite 5)
Jeder Chunk hat seine eigene Zeile mit seinem eigenen Embedding.
Einfacher Vergleich:
- Vektordatenbank: Bücher nach Bedeutung: “Alle Tiere zusammen, alle Fahrzeuge zusammen…”ding.
- Normale Bibliothek: Bücher nach Alphabet: “Affe, Auto, Bär, Boot…”

4. Die KI startet die intelligente Bedeutungssuche
Schritt 1: Deine Frage wird zu einem Embedding
- “Wie erziehe ich meinen Welpen?” → [0.25, -0.75, 0.55, …] (1536 Zahlen)
Schritt 2: Vergleich mit ALLEN Chunk-Embeddings
- Dein Fragen-Embedding wird mit allen gespeicherten Chunk-Embeddings verglichen
- Die Kosinus-Ähnlichkeit berechnet für jeden Chunk einen Ähnlichkeitswert
Schritt 3: Die besten Chunks werden gefunden
- Chunk A “Welpen brauchen klare Regeln”: 95% ähnlich ✅
- Chunk B “Positive Verstärkung ist wichtig”: 89% ähnlich ✅
- Chunk C “Katzen sind anders als Hunde”: 12% ähnlich ❌
Schritt 4: Top-3 Chunks werden ausgewählt Standard: Die 3 ähnlichsten Chunks werden an das LLM weitergegeben
Das Ergebnis: Die KI findet automatisch die relevantesten Textabschnitte für deine Frage!
Beispiel der intelligenten Suche:
- Du fragst: “Wie erziehe ich meinen Welpen?”
- Die KI findet auch Artikel über “Hundeerziehung”, “Welpenschule” und “Tiererziehung”
- Warum das funktioniert: Alle diese Begriffe haben ähnliche Zahlen-Codes!
Chunks beschaffen die Information, Tokens verarbeiten sie sprachlich. Bei klassischen LLMs (ohne Retrieval) gibt es keine Chunks, nur Tokens.
Embeddings und Vektordatenbanken sind die geheimen Helden bei Typ 3 (RAG-Systemen) – sie machen die intelligente, bedeutungsbasierte Suche erst möglich! Typ 2 (“klassische” IR-Systeme) arbeitet mit traditionellen Methoden wie TF-IDF und BM25. (Zilliz, 2025) [3], (IBM Research, 2024) [4] & (AWS, 2024) [5].
Station3: Das “Gehirn” der KI arbeitet
Was passiert: Die KI verarbeitet nun alle verfügbaren Informationen. In dieser Phase findet die eigentliche “Denkarbeit” statt.
1. Verankerung in der Realität – Grounding (nur bei RAG Systemen)
- Die KI versucht, ihre Antwort auf echte Fakten zu stützen und nutzt die gefundenen Chunks aus Station 2 als “Anker” für ihre Antwort
- Grounding = Die gefundenen Chunks SIND die Erdung der Antwort
- Wie ein Detektiv, der seine Theorien mit Beweisen untermauert

Unterschied zu bei traditionellen LLMs
- Arbeiten nur mit internem Trainingswissen
- Keine externen Chunks = kein Grounding möglich
Unterschied bei reinen IR-Systemen
- Finden relevante Dokumente, aber formulieren keine Antworten
- Du musst selbst die Informationen interpretieren
2. Logisches Denken – Reasoning
- Die KI zieht Schlüsse und löst Probleme
- Wie ein Mathematiker, der Schritt für Schritt rechnet

Hier passiert der “Aha-Moment” – die KI verbindet Frage mit Wissen
Reasoning bei RAG-Systemen: Context Assembly + Attention
Schritt 1: Prompt-Engineering – die KI baut einen “Super-Prompt” zusammen
"Basierend auf folgenden Informationen:
[Chunk 1: Welpen brauchen klare Regeln...]
[Chunk 2: Positive Verstärkung ist wichtig...]
[Chunk 3: Konsistenz beim Training...]
Beantworte die Frage: Wie erziehe ich meinen Welpen?"Schritt 2: Attention-Mechanismus
- Die KI “schaut hin und her” zwischen der ursprünglichen Frage und den Chunks
- Wie ein Detektiv, der Hinweise miteinander verbindet
- Attention-Weights zeigen, welche Chunk-Teile für welche Frage-Teile relevant sind
Schritt 3: Inference (Schlussfolgerung)
- Das LLM kombiniert die relevanten Chunk-Informationen
- Es “übersetzt” die gefundenen Fakten in eine zusammenhängende Antwort
- Das ist der Moment, wo die spezifische Antwort vorbereitet wird
Reasoning bei traditionellen LLMs: Sophisticated Pattern Matching
Schritt 1: Aktivierung statistischer Muster
- Die tokenisierte Frage aktiviert ähnliche statistische Muster aus den Trainingsdaten
- Wie ein Mensch, der bei “Welpe” automatisch an “Training”, “Erziehung” denkt
- Aber: Basiert auf Häufigkeitsverteilungen, nicht auf echtem Verständnis
Schritt 2: Probabilistische Mustererkennung
- Das LLM erkennt statistische Korrelationen zwischen Begriffen in seinen Trainingsdaten
- Attention fokussiert auf die wahrscheinlichsten erlernten Verbindungen
- Nicht: Echtes “Retrieval”, sondern Pattern-Matching basierend auf Co-Occurence-Statistiken
Schritt 3: Probabilistische Synthese + Chain of Thought
- Aus den aktivierten Mustern wird eine wahrscheinlichkeitsbasierte Antwort zusammengesetzt
- Problem: Sophisticated pattern matching kann versagen bei:
- Neuen Situationen außerhalb der Trainingsdaten
- Irrelevanten Zusatzinformationen (siehe Apple-Studie GSM-NoOp)
- Änderungen in Symboldarstellungen oder Begriffen
- Keine echte Verifikation gegen logische Regeln möglich
Chain-of-Thought als Reasoning-Verstärker
Bei RAG-Systemen:
- CoT hilft beim strukturierten Durcharbeiten der gefundenen externen Informationen
- Jeder Schritt ist an verifizierbaren Quellen verankert
Bei traditionellen LLMs:
- CoT ist eine Prompting-Technik, die pattern matching strukturierter macht
- Erzeugt den Anschein von logischem Denken, basiert aber weiterhin auf statistischen Mustern
- Vorteil: Macht das “Denken” transparent und oft präziser
- Nachteil: Kann bei unbekannten Problemen oder Störinformationen zusammenbrechen
Die “Magie” entschlüsselt:
- RAG: Attention verknüpft Frage mit externen Fakten → spezifische, messbare Antworten
- Klassisches LLM: Attention verknüpft Frage mit statistischen Mustern → allgemeine, vertraute Antworten
Die RAG-Antwort ist spezifischer, nachprüfbar und praktisch umsetzbar, während die LLM-Antwort allgemeiner und “bekannt klingend” ist. Nicht nur die Grundlage ist unterschiedlich, sondern auch die Qualität und Präzision der Ergebnisse!
Station 4: Die Antwort wird generiert
Was passiert: Das LLM führt die technische Textgenerierung durch – von der Wahrscheinlichkeitsberechnung bis zur finalen Token-Auswahl. Der Generierungsprozess umfasst:
1. Wahrscheinlichkeit
- Für jedes mögliche nächste Wort wird eine Wahrscheinlichkeit berechnet
- Wie ein Wahrsager, der die Chancen für verschiedene Ereignisse abwägt
2. Wortauswahl (Sampling)
Sampling ist der Prozess, bei dem ein LLM das nächste Token aus einer Wahrscheinlichkeitsverteilung auswählt.
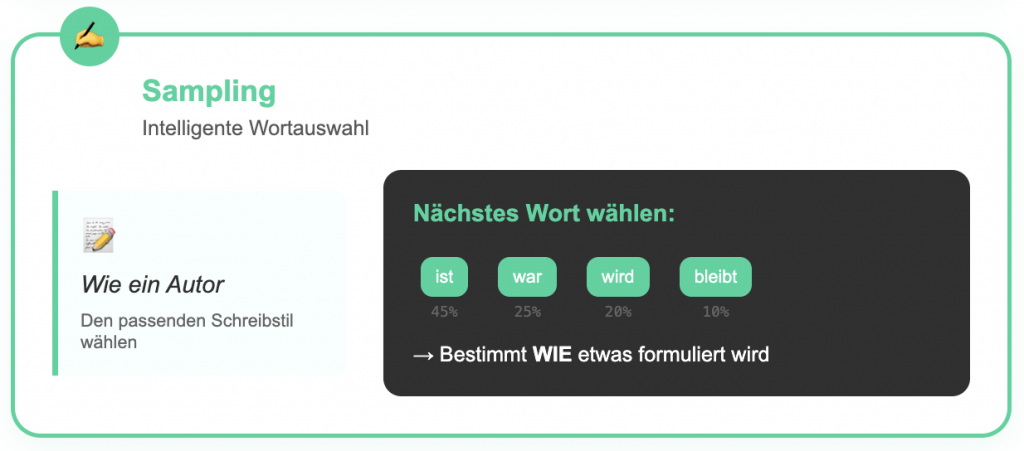
Die wichtigsten Sampling-Methoden:

1. Greedy Sampling
- Methode: Stets das wahrscheinlichste nächste Token
- Vorteil: Hohe Vorhersehbarkeit und Genauigkeit
- Nachteil: Repetitive, wenig kreative Texte
2. Random Sampling
- Methode: Zufällige Auswahl basierend auf Wahrscheinlichkeiten
- Vorteil: Hohe Vielfalt und Kreativität
- Nachteil: Mögliche Inkohärenz oder Unlogik
3. Top-k Sampling
- Methode: Auswahl aus den k wahrscheinlichsten Tokens
- Vorteil: Guter Kompromiss zwischen Vorhersehbarkeit und Vielfalt
- Anwendung: Vermeidung unwahrscheinlicher oder unsinniger Wörter
4. Top-p Sampling (Nucleus Sampling)
- Methode: Dynamische Auswahl basierend auf kumulativer Wahrscheinlichkeit
- Vorteil: Kontextbezogene und adaptive Tokenauswahl
- Innovation: Vermeidet das Problem fixer k-Werte
Wichtig: Die Wahl der Sampling-Methode beeinflusst maßgeblich Kreativität, Kohärenz und Vorhersehbarkeit des generierten Textes (Hugging Face, 2024) [5].
Das Zusammenspiel: Grounding, Reasoning und Sampling
| Komponente | Rolle | Bestimmt | Metapher |
|---|---|---|---|
| Grounding | Wissen verankern | WAS gesagt wird | Wie ein Detektiv (Theorie mit Beweisen untermauern) |
| Reasoning | Denken & Schlussfolgern | WARUM etwas gesagt wird | Wie ein Mathematiker (Logik & Schlussfolgerung) |
| Sampling | Wortauswahl-Technik | WIE etwas formuliert wird | Wie ein Autor mit passendem Schreibstil |
Die komplette Prompt-to-Response Pipeline
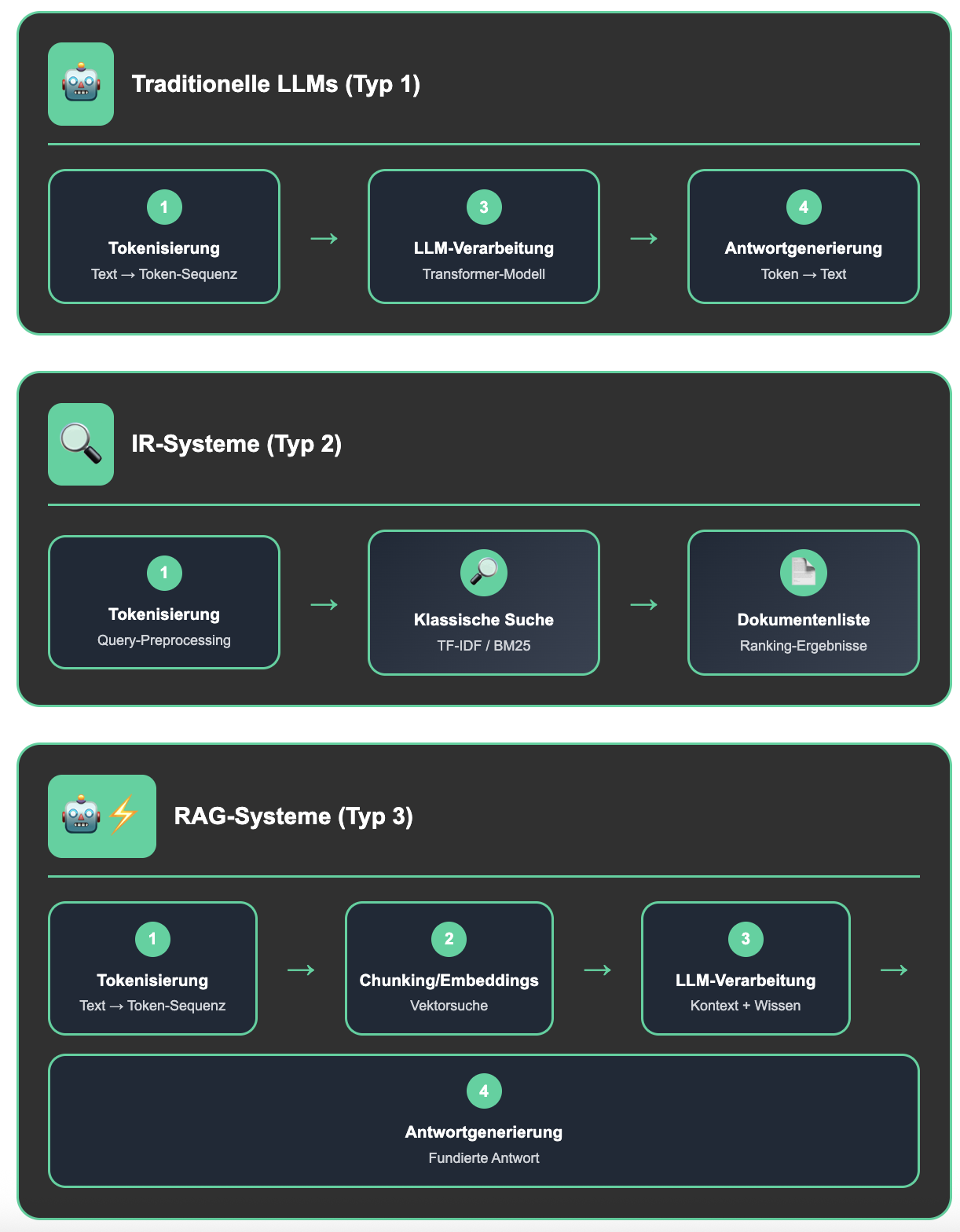
- Traditionelle LLMs (Typ 1): Station 1 (Tokenisierung) → Station 3 (LLM-Verarbeitung) → Station 4 (Antwortgenerierung)
- IR-Systeme (Typ 2): Station 1 (Tokenisierung) → Klassische Suche (TF-IDF/BM25) → Dokumentenliste
- RAG-Systeme (Typ 3): Station 1 (Tokenisierung) → Station 2 (Chunking/Embeddings/Vektorsuche) → Station 3 (LLM-Verarbeitung) → Station 4 (Antwortgenerierung)
Das große Problem: KI-Halluzinationen
Was sind KI Halluzinationen und warum entstehen sie?
Manchmal erfindet die KI Informationen, die falsch sind, aber überzeugend klingen. Die KI versucht immer, eine Antwort zu geben – auch wenn sie nicht genug weiß. Dann “rät” sie und präsentiert die Vermutung als Fakt.
Wie wird das verhindert?
- Gute Recherche-Systeme (RAG)
- Verankerung in vertrauenswürdigen Quellen
- Kontinuierliche Überwachung und Qualitätskontrolle
- Verbesserung der KI-Modelle durch bessere Trainingsdaten
Die Zukunft: Schritt für Schritt bessere KI
Die Entwicklung geht in Richtung KI-Systeme, die:
- Kreativer sind (wie ein Künstler)
- Genauer sind (wie ein Wissenschaftler)
- Aktueller sind (wie ein Journalist)
- Vertrauenswürdiger sind (wie ein Experte)
Halluzinationen vollständig zu eliminieren bleibt eine offene Forschungsfrage, aber deutliche Verbesserungen sind bereits erkennbar.
Fazit: Eine komplexe Reise in Sekunden
Was für uns wie eine einfache Frage und Antwort aussieht, ist tatsächlich eine komplexe Reise durch verschiedene technische Systeme – alles in wenigen Sekunden bis Minuten, je nach Komplexität der Anfrage. Die KI von heute kombiniert riesige Mengen an Wissen mit cleveren Suchmethoden und kreativer Textgenerierung, um uns möglichst hilfreiche Antworten zu geben.
Das Wichtigste zum Merken: Moderne KI ist am besten, wenn sie nicht nur “aus dem Kopf” antwortet, sondern auch aktuelle Informationen recherchiert und diese mit ihrem gelernten Wissen kombiniert.
Die neue Marketing-Disziplin: Sichtbarkeit in KI-Antworten
Die digitale Landschaft verändert sich: Generative KI-Anwendungen wie ChatGPT, Claude, oder Perplexity könnten den klassischen Suchmaschinen schon bald erhebliche Marktanteile abnehmen. Für Unternehmen stellt sich die entscheidende Frage: Wie bleiben wir sichtbar, wenn Nutzer ihre Informationen nicht mehr nur über Suchmaschinen, sondern direkt über KI-gestützte Antwortmaschinen beziehen? Die Bezeichnungen Large Language Model Optimization (LLMO), Generative Engine Optimization (GEO) oder Answer Engine Optimization (AEO) adressieren genau diese Herausforderung – sie beschreiben die logische Weiterentwicklung von SEO im Zeitalter der generativen KI.
Warum das wichtig wird:
- KI-Systeme werden zunehmend zur ersten Anlaufstelle für Informationen
- Traditionelle SEO sollte weiterentwickelt werden
- Neue Strategien sind nötig, um für KI-Systeme “findbar” und “zitierfähig” zu werden

Mehr dazu: In dem Blogartikel “Was bedeutet LLMO/GEO/AEO” erfährst du warum SEO weiterhin relevant bleibt, wie sich die neuen Disziplinen der Suchlandschaft einordnen lassen, warum sie für deine digitale Präsenz zunehmend an Bedeutung gewinnen und welche vielversprechenden Optimierungspotenziale sich daraus ergeben.
Quellen
[1]: GeeksforGeeks (2024). How to Build RAG Pipelines for LLM Projects? GeeksforGeeks.
[2]: NIVIDIA (2025) What Is Retrieval-Augmented Generation, aka RAG?
[3]: Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
[4]: IBM (2024). What is retrieval-augmented generation?
[5]: AWS (2024) Was ist Retrieval-Augmented Generation (RAG)?
[6]: Hugging Face (2024) How to generate text: using different decoding methods for LLM with Transformers


0 Kommentare